����ѧ�ú���ũҵ��ѧ����ԭ��(ר����)���Ͽ��Դ�
 |
| A:����������ĸ�� B:�ķ����ż��� C:��ֹ״̬���� D:����״̬���� |
|
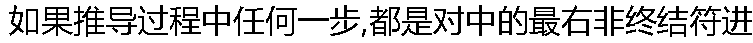 ���滻,��������Ƶ���( )�� ���滻,��������Ƶ���( )�� |
| A:ֱ���Ƶ� B:�����Ƶ� C:�����Ƶ� D:�����Ƶ� |
|
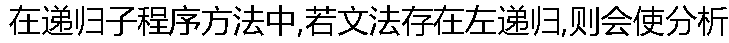 ���̲���( )�� ���̲���( )�� |
| A:���� B:�Ƿ����� C:���ε��� D:����ѭ�� |
|
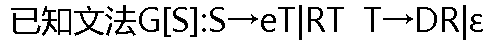 R��dR|�� D��a|bd ,��FIRST(S)=( )�� R��dR|�� D��a|bd ,��FIRST(S)=( )�� |
| A:{ e } B:{ e,d,a,b } C:{ e,d } D:{ e,d,a,b,�� } |
|
 )�� )�� |
| A:�����ķ� B:LR(1)�ķ� C:LL(1)�ķ� D:�������ķ� |
|
����ͼ��ʾFA�ȼ۵�DFA��( )��
 |
A: B: B: C: C: D:����������� D:����������� |
|
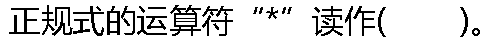 |
| A:�� B:�հ� C:�� D:���� |
|
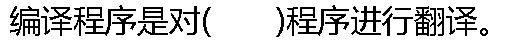 |
| A:������ B:�������� C:������� D:��Ȼ���� |
|
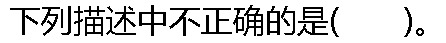 |
| A:���ķ���ʹ�õݹ����,ʹ�������������Ĺ���ȥ��������ϵ����ԡ� B:�����Ƶ�Ҳ�ƹ淶�Ƶ�,�ù淶�Ƶ��Ƶ����ij�Ϊ�淶���͡� C:�淶�Ƶ��������,��Ϊ�����Լ,Ҳ��Ϊ�淶��Լ�� D:����һ���Ǿ���,���Ͳ�һ���Ǿ��ӡ� |
|
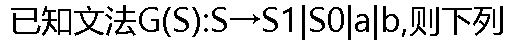 ѡ���в����ɸ��ķ��Ƶ�������( )�� ѡ���в����ɸ��ķ��Ƶ�������( )�� |
| A:b110 B:a000 C:b0a0 D:a101 |
|
 |
| A:BASIC B:C C:FORTRAN D:PASCAL |
|
 |
| A: ���� B: ���� C:���� D:����ʽ |
|
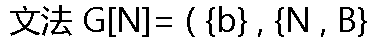 , N , {N��b�� bB , B��bN} ),���ķ������� ��������_____�� , N , {N��b�� bB , B��bN} ),���ķ������� ��������_____�� |
| A: L(G[N])={bi�� i �� 0} B:L(G[N])={b2i�� i�� 0} C:L(G[N])={b2i+1�� i �� 0} D:L(G[N])={b2i+1�� i �� 1} |
|
��������� , ����������������_____��
(1) �����������������ɵ� (2) �������ʴ�����ι�������˵����
(3) ��������˵������ι��ɳ���� (4) ��������Ľṹ |
| A: (2)(3) B:(2)(3)(4) C:(1)(2)(3) D:(1)(2)(3)(4) |
|
 |
| A:a+b/c+d B:(a+b)/(c+d) C:a+b/(c+d) D: a+b+c/d |
|
 |
| A:�����Գ���͵ͼ����Գ��� B:���ͳ���ͱ������ C:�������Ͳ���ϵͳ D:ϵͳ�����Ӧ�ó��� |
|
 |
| A:����� B:�м�������� C:�ʷ����� D:Ŀ��������� |
|
 |
| A:Ψһ�� B:��Ψһ�� C:����Ψһ���ÿ��ܲ�Ψһ D:������ |
|
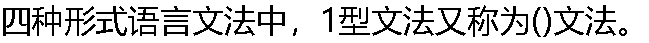 |
| A:����ṹ�ķ� B:ǰ�������ķ� C:ǰ�����й��ķ� D:�����ķ� |
|
 |
| A:�ݹ�� B:ǰ�����ص� C:�����Ե� D:�����Ե� |
|
 |
| A:���� B:�ս���� C:���ս���� D:���� |
|
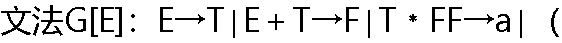 E�����ķ�����E��F�~(E��T)�ļ��������з��Ŵ��е�()�٣�E��T����E��T��F��F�~(E��T)�� E�����ķ�����E��F�~(E��T)�ļ��������з��Ŵ��е�()�٣�E��T����E��T��F��F�~(E��T)�� |
| A:�ٺ͢� B:�ں͢� C:�ۺ͢� D:�� |
|
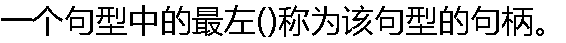 |
| A:���� B:���� C:�ض��� D:�ս���� |
|
 ��������ɣ������Ż���Ŀ��������ɵ�������֣���Ӧ����()�� ��������ɣ������Ż���Ŀ��������ɵ�������֣���Ӧ����()�� |
| A:ģ��ִ���� B:������ C:�������ͳ������� D:����ִ���� |
|
 �ɣ������Ż���Ŀ��������ɵ�������֡� �ɣ������Ż���Ŀ��������ɵ�������֡� |
| A:����� B:�ķ����� C:���Է��� D:���ͷ��� |
|
 |
|
|
 ? ? |
|
|
��������ij��� �� procedure p(x, y, z)�� begin y:=x+y; z:=z*z; end begin A:=2; B:=A*2; P(A, A, B); Print A, B end. ���ʣ����������ݵķ�ʽ�ֱ���ô���ַ�ʹ�ֵʱ������ִ�к���� A, B��ֵ��ʲô? |
|
|
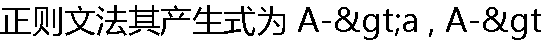 ;Bb, A,B��VN , a �� b��VT �� ( ) ;Bb, A,B��VN , a �� b��VT �� ( ) |
| A:��ȷ B:���� |
|
 |
| A:��ȷ B:���� |
|
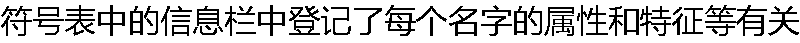 ��Ϣ�������͡���������ռ��Ԫ��С����ַ�ȵȡ� () ��Ϣ�������͡���������ռ��Ԫ��С����ַ�ȵȡ� () |
| A:��ȷ B:���� |
|
 ��ȷ��ָ�������ص㡣() ��ȷ��ָ�������ص㡣() |
| A:��ȷ B:���� |
|
 ) ) |
| A:��ȷ B:���� |
|
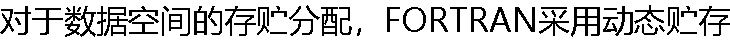 ������ԡ�() ������ԡ�() |
| A:��ȷ B:���� |
|
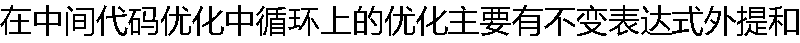 ��������ǿ��() ��������ǿ��() |
| A:��ȷ B:���� |
|
 () () |
| A:��ȷ B:���� |
|
 �����ԡ�() �����ԡ�() |
| A: ��ȷ B: ���� |
|
 |
| A: ��ȷ B: ���� |
|





