青书学堂河南科技大学数据库原理(专升本)网上考试答案
 是( )。 是( )。 |
| A:学号char (8) NOT NULL CONSTRAINT un_ no UNIQUE B:学号char (8) NOT NULLCONSTRAINTPK_学生表PRIMARY KEY C:性别char (2) NOT NULL check (性别=‘男'or性别=‘女') D:学号char (8) NOT NULL |
|
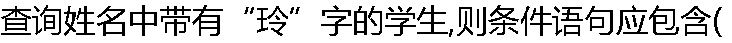 )。 )。 |
| A:WHERE姓名LIKE %‘玲’ B:WHERE姓名LIKE *%玲%' C: WHERE姓名%‘LIKE玲LIKE’ D: WHERE姓名LIKE‘玲%' |
|
 |
| A:遵守第三范式标准的数据库设计 B:尽可能的建立触发器 C:适当使用视图 D:尽可能多地采用外键 |
|
 |
| A:操作系统 B:系统数据库 C:用户数据库 D:事务日志 |
|
 应该包含( )。 应该包含( )。 |
| A:SELECT MIN (年龄)AS平均FROM学生表 B:SELECT MAX (年龄)AS平均FROM学生表 C:SELECT AVG (年龄)AS平均FROM学生表 D:SELECT COUNT (年龄)AS平均FROM学生表 |
|
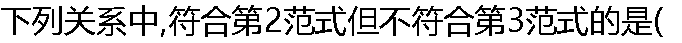 )。 )。 |
A:姓名 性别 单位 城市 邮编.联系电话 办公电话 手机号
张华 男 天津大学 北京 110110 3676532 13511299898 B:学号 姓名 性别 专业 课程号课程名课程学分 成绩 0101002 张华 男 电子 A02计算机网络 5 68 C:学号 姓名 性别 专业 0101002 张华 男 电子 D:姓名 性别 单位 城市 邮编 办公电话 手机号 王明 男 天津大学 北京 110110 3676512 13511299898 |
|
对于教学管理数据库,当采用事务控制机制时,利用UPDATE语句将学生表中学号为“002”的学生的学号改为“2002',还没来得急对成绩表进行更新操作,突然停电了,SQL 的事务
控制功能将( )。 |
| A:保留对学生表的修改,机器重新启动后,自动进行对成绩表的更新 B:保留对学生表的修改,机器重新启动后,提示用户对成绩表的进行更新 C:清除对学生表的修改 D:清除对学生表的修改,机器重新启动后,自动进行对学生表和成绩表的更新 |
|
 |
| A:基本表的某列中记录数量特别多 B:基本表的某列中记录数量特别少 C:经常进行插入操作的基本表的某列 D:经常进行制除操作的基本表的某列 |
|
 ) 做为数据类型。 ) 做为数据类型。 |
| A:数值数据类型 B:字符型 C:日期时间型 D:位型 |
|
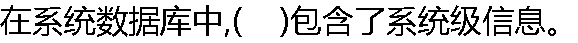 |
| A:master 数据库 B:tempdb 数据库 C:model 数据库 D:msdb 数据库 |
|
设课程成绩表的结构为(学号,课程号,成绩),如果希望查询出“成绩大于90分且课
程号首字母为A的所有记录”,则对应的SQL语句是( )。 |
| A: SELECT * FROM课程成绩表WHERE成绩 gt;90 AND课程号LIKE A% B: SELECT * FROM课程成绩表WHERE成绩 gt;900R课程号LIKE A% C: SELECT* FROM课程成绩表WHERE成绩 gt;90AND课程号LIKE‘A%' D: SELECT* FROM课程成绩表WHERE 成绩 gt;900R课程号LIKE ‘A%' |
|
 )。 )。 |
| A: Max函数 B: Min 函数 C: Count 函数 D: Avg 函数 |
|
 )。 )。 |
| A: INSERT B: BACKUP C: RESTORE D: UPDATE |
|
 |
| A:单列索引 B:惟一索引 C:聚集索引 D:事务日志索引 |
|
 层次的安全控制,分别是( )。 层次的安全控制,分别是( )。 |
| A:操作系统、服务器、数据库、表和列 B:表和列、数据库、服务器、操作系统 C:操作系统、数据库、网络、列 D:列、网络、数据库、操作系统 |
|
 char. Ntext 等几种双字节数据类型实际上是一种( )。 char. Ntext 等几种双字节数据类型实际上是一种( )。 |
| A: Unicode 数据类型 B: ASCII 数据类型 C:时间戳数据类型 D:数值型类型 |
|
 |
| A:教师(编号,姓名,系所编号,系所名称) B:教师(编号,姓名,职称) C:教师(编号,姓名,课程号,课程名称) D:教师(编号,姓名,系所编号,系所主任姓名) |
|
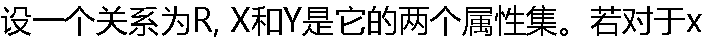 上的每个值都有Y上的一个惟一值与之对应,则称X和Y ( )。 上的每个值都有Y上的一个惟一值与之对应,则称X和Y ( )。 |
| A:属于第一范式 B:属于第二范式 C:具有函数依赖关系 D:具有非函数依赖关系 |
|
在物理层面,SQLServer数据库是由数据文件和事务日志文件两个操作系统文件组成的,
它们的后缀分别是( )。 |
| A: MDF和LDF B: LDF和MDF C: DAT和LOG D: LOG和DAT |
|
 )的字段是( )。 )的字段是( )。 |
| A:物资类别 B:物资编码 C:规格型号 D:计划单价 |
|
 模型通常由三部分组成( )。 模型通常由三部分组成( )。 |
| A:数据结构、关系操作集合和关系的完整性 B: 一级模式、二级模式、三级模式 C:数据库、数据表、索引 D:数据库、数据表、视图 |
|
设学生表和课程表的结构分别为(学号,姓名)和(学号,课程号,成绩),如果希望
查询出“成绩大于90分的学生姓名”,则对应的SQL语句是( )。 |
| A:SELECT 姓名FROM学生表WHERE学生表学号=课程表学号AND课程表,成绩 gt;90 B:SELECT 姓名FROM课程表WHERE学生表学号=课程表学号AND课程表.成绩 gt;90 C:SELECT 姓名FROM学生表,课程表WHERE学生表学号=课程表学号OR课程表成绩 gt;90 D:SELECT 姓名FROM学生表,课程表WHERE学生表学号=课程表学号AND课程表成绩 gt;90 |
|
 是( )。 是( )。 |
| A:INSERT DATABASE B:BACKUP DATABASE C:RESTOREDATABASE D:UPDATEDATABASE |
|
 个安全性阶段( )。 个安全性阶段( )。 |
| A:登录验证、操作验证 B:操作验证、登录验证 C:身份验证、权限认证 D:权限认证、身份验证 |
|
 成的新关系称为( )。 成的新关系称为( )。 |
| A:两个关系的积 B:两个关系的并 C:两个关系的交 D:两个关系的差 |
|
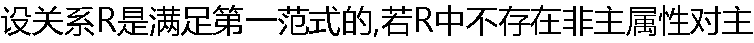 键的部分函数依赖,则R符合( )。 键的部分函数依赖,则R符合( )。 |
| A:第二范式 B:第三范式 C:BNC范式 D:第四范式 |
|
 |
| A:索引必须创建在主关键字之上 B:索引与基本表分开存储 C:索引是为了提高查询速度而创建的 D:索引会在一定程度 上影响增删改操作的效率 |
|
 构是( )。 构是( )。 |
| A:模式、外模式和内模式 B:内模式、.外模式和模式 C:外模式、模式和内模式 D:外模式、内模式和模式 |
|
 件语句应该是( )。 件语句应该是( )。 |
| A:Where姓名%“王’ B:Where姓名IKE “王%' C:Where姓名%‘LKE王' D:Where姓名LIKE‘王' |
|
 |
| A:SUN(列名) B:MAX(列名) C:AVG(列名) D:COUNT(*) |
|
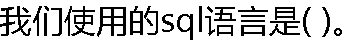 |
| A:结构化查询语言 B:标准化查询语言 C:Microsoft SQL Server 数据库管理系统的专用语言 D:多种数据库管理系统使用的通用语言 |
|
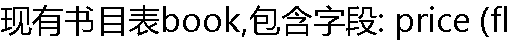 oat);现在查询一条书价最高的书目的详细信息,以下语句正确的是( )。 oat);现在查询一条书价最高的书目的详细信息,以下语句正确的是( )。 |
| A:select top 1 * from book order by price asc B:select top 1 * from book order by price desc C:select top 1 * from book where price=(select max (price)from book) D:select top 1 * from book where price= max(price) |
|
在 SQL Server数据库(排序规则为默认值)中,有一个产品表products,你想按照价格
从小到大的顺序显示所有产品的名称(productname)和价格(price),可以实现该功能的T-SQL语句是( )。 |
| A:SELECT productname , price from products order by price ASC B:SELECT productname , price from products order by price DESC C:SELECT productname , price from products order by price D:SELECT productname and price from products order by price DESC |
|
 )。 )。 |
| A:truncate table book B:drop table book C:delete from book D:delete * from book |
|
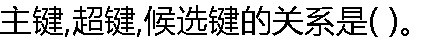 |
| A:主键一定是超键,候选键不一定是超键 B:候选键一定是主键,候选键不一定是超键 C:超键不一定是主键,候选键一定是超键 D:主键一定是超键,候选键一定是超键 |
|
| 什么是数据库的重组、重构? |
|
|





