青书学堂河南林业职业学院数据化运营(高起专)网上考试答案
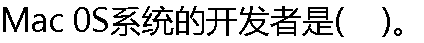 |
| A:微软公司 B:惠普公司 C:苹果公司 D: IBM 公司 |
|
 |
| A:彼得●德鲁克 B:舍恩伯格 C:蒂姆●伯纳斯一李 D:斯科特●布朗 |
|
 |
| A:在数据基础上倾向于全体数据而不是抽样数据 B:在分析方法上更注重相关分析而不是因果分析 C:在分析效果上更追究效率而不是绝对精确 D:在数据规模上强调相对数据而不是绝对数据 |
|
 )。 )。 |
| A:不预先设定数据归类类目,完全根据数据本身性质将数据聚合成不同类别 B:要求同类数据的内容相似度尽可能小 C:要求不同类数据的内容相似度尽可能小 |
|
 )。 )。 |
| A:1KB lt; 1MB lt; 1GB B:基本单位是字节(Byte) . C:一个汉字需要一个字节的存储空间 D:一个字节能够容纳一个英文字符 |
|
 。 。 |
| A:网络公司能够捕捉到用户在其网站上的所有行为 B:用户离散的交互痕迹能够为企业提升服务质量提供参考 C:数字轨迹用完即自动删除 D:用户的隐私安全很难得以规范保护 |
|
 |
| A:数据存储和备份规范 B:数据管理和维护 C:数据价值发觉和利用 D:数据应用开发和管理 |
|
 |
| A:互联网 B:物联网 C:综合国力 D:自然资源 |
|
 新的航海路线图,标明了大风与洋流可能发生的地点。这体现了大数据分析理念中的( )。 新的航海路线图,标明了大风与洋流可能发生的地点。这体现了大数据分析理念中的( )。 |
| A:在数据基础.上倾向于全体数据而不是抽样数据 B:在分析方法上更注重相关分析而不是因果分析 C:在分析效果上更追究效率而不是绝对精确 D:在数据规模上强调相对数据而不是绝对数据 |
|
 |
| A:数据规模大 B:数据类型多样 C:数据处理速度快 D:数据价值密度高 |
|
 |
| A:数字城市 B:物联网 C:联网监控 D:云计算 |
|
 |
| A:数据重组是数据的重新生产和重新采集 B:数据重组能够使数据焕发新的光芒 C:数据重组实现的关键在于多源数据融合和数据集成 D:数据重组有利于实现新颖的数据模式创新 |
|
 采集技术的应用。 采集技术的应用。 |
| A:统计报表 B:网络爬虫 C:API 接口 D:传感器 |
|
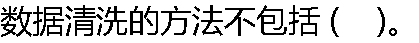 |
| A:缺失值处理 B:噪声数据清除 C:一致性检查 D:重复数据记录处理 |
|
 值越高。 值越高。 |
| A:规模 B:活性 C:关联度 D:颗粒度 |
|
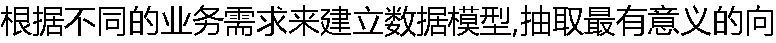 量,决定选取哪种方法的数据分析角色人员是?( ) 量,决定选取哪种方法的数据分析角色人员是?( ) |
| A:数据管理人员 B:数据分析员 C:研究科学家 D:软件开发工程师 |
|
 |
| A:金融 B:电信 C:互联网 D:公共管理 |
|
 |
| A:微软 B:百度 C:谷歌 D:阿里巴巴 |
|
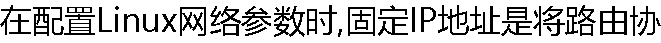 议配置为( )。 议配置为( )。 |
| A:static B:dynamic C:immutable D:variable |
|
 |
| A:3份 B:2份 C:1份 D:不确定 |
|
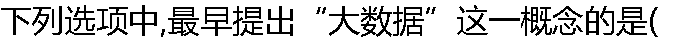 )。 )。 |
| A:贝恩 B:麦肯锡 C:吉拉德 D:杰弗逊 |
|
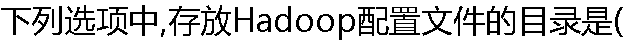 ?)。 ?)。 |
| A:include B:bin C:libexec D:etc |
|
 op集群( )。 op集群( )。 |
| A:name node B:data node C:secondary name node D:yarn |
|
 )。 )。 |
| A:HDFS采用的是主备架构 B:HDFS采用的是主从架构 C:HDFS采用的是从备架构 D:以上说法均错误 |
|
 ? ? )步。 ? ? )步。 |
| A:两 B:三 C:四 D:五 |
|
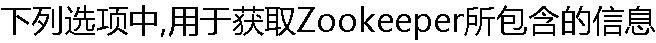 的Shell命令是(? ? ? )。 的Shell命令是(? ? ? )。 |
| A:ls B:ls2 C:r D:get |
|
 |
| A:HDFS HA可以解决单点故障问题 B:HDFS Federation使得HDFS的命名服务能够水平扩展 C:第二名称节点无法解决单点故障问题 D:第二名称节点是热备份,而HDFS HA不是热备份 |
|
 ello bgdata hll hado ,经过map函数处理后直接输出的结果应该是(没有发生combine和merge操作)(? ? ?)。 ello bgdata hll hado ,经过map函数处理后直接输出的结果应该是(没有发生combine和merge操作)(? ? ?)。 |
| A: lt;ll.,2 gt;. lt;*bigdata',1 gt;和 lt;'hadoop',1 gt; B: lt;elol, lt;1,1 gt; gt;. lt;'bigdatai ,1 gt;和'hadoop',1 gt; C: lt;llo',1,1 gt;. lt;bigdata' ,1 gt;和 lt;'hadoop',1 gt; D: lt;“hello”,1 gt;、 lt;“hello”,1 gt;、 lt;“bigdata”,1 gt;和 lt;“hadoop”,1 gt; |
|
 |
| A:HBase是针对谷歌BigTable的开源实现,舸靠高性能的图数据库 B:在向数据库中插入记录时, HBase和关系数据库一样,每次都是以“行为单位把整条记录插入数据库 C:HBase数据库表可以设置该表任意列作为索引 D:HBase是-种NoSQL 数据库 |
|
 插入一记录{id:2015001,name :Mary,{score math}:88},其id作为行键,其中 ,在插入数学成绩88分时,正确的命令是(? )。 插入一记录{id:2015001,name :Mary,{score math}:88},其id作为行键,其中 ,在插入数学成绩88分时,正确的命令是(? )。 |
| A:put 'student,'score:math';88' B:put'student',‘2015001','score:math','88' C:put 'student',2015001';'88' D:put 'student ,2015001,'math';'88' |
|
 |
| A:大数据具有体量大、结构单一、时效性强的特征 B:处理大数据需采用新型计算架构和智能算法等新技术 C:大数据的应用注重相关分析而不是因果分析 D:大数据的应用注重因果分析而不是相关分析 E:大数据的目的在于发现新的知识与洞察并进行科学决策 |
|
 ( )。 ( )。 |
| A:投资入股互联网电商行业 B:打通多源跨域数据 C:提高分析挖掘能力 D:自行开发数据产品 E:实现科学决策与运营 |
|
 |
| A:线性回归分析 B:非线性回归分析 C:一元回归分析 D:多元回归分析 E:综合回归分析 |
|
 |
| A:格式不规范 B:编码不统一 C:意义不明确 D:与实际业务关系不大 E:数据不完整 |
|
 ,错误的是( )。 ,错误的是( )。 |
| A:传统营销模式比基于大数据的营销模式投入更小 B:传统营销模式比基于大数据的营销模式针对性更强 C:传统营销模式比基于大数据的营销模式转化率低 D:基于大数据的营销模式比传统营销模式实时性更强 E:基于大数据的营销模式比传统营销模式精准性更强 |
|
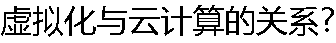 |
|
|





