青书学堂南阳理工学院数据结构(专升本)网上考试答案
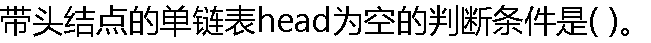 |
| A:head==NULL B:head->next==NULL C:head->next==head D:head!=NULL |
|
 |
| A:head==NULL B:head->next==NULL C:head->next==head D:.head!=NULL |
|
 )的( )。 )的( )。 |
| A:先序遍历 B:中序遍历 C:后序遍历 D:按层遍历 |
|
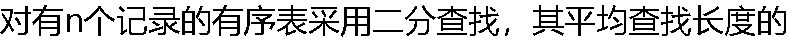 量级为( )。 量级为( )。 |
| A:O(log2n) B:O(nlog2n) C:O(n) D:O(n2) |
|
 点和删除最后一个结点,则采用( )存储方式最节省空间。 点和删除最后一个结点,则采用( )存储方式最节省空间。 |
| A:单链表 B:双链表 C:带头结点的双循环链表 D:单循环链表 |
|
 表示,则所有顶点邻接表中的结点总数为( )。 表示,则所有顶点邻接表中的结点总数为( )。 |
| A:2*n B:2*e C:n D:e |
|
 的范围从0~8,列下标j的范围从1~10。若a按行存放,元素a[8,5]的起始地址与当a按列存放时的元素( )的起始地址一致(每个字符占一个字节)。 的范围从0~8,列下标j的范围从1~10。若a按行存放,元素a[8,5]的起始地址与当a按列存放时的元素( )的起始地址一致(每个字符占一个字节)。 |
| A:a[8,5] B:a[3,10] C:a[5,8] D:a[0,9] |
|
 |
| A:n(n-1)/2 B:n(n-1) C:n(n-2) D:2n |
|
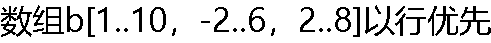 的顺序存储,设第一个元素的首址是100,每个元素的长度为3。元素b[5,0,7]的存储首址为( )。 的顺序存储,设第一个元素的首址是100,每个元素的长度为3。元素b[5,0,7]的存储首址为( )。 |
| A:900 B:912 C:910 D:913 |
|
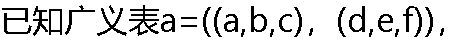 从a中取出原子e的运算是( )。 从a中取出原子e的运算是( )。 |
| A:tail(head(a)) B:head(tail(a)) C:head(tail(tail(head(a)))) D:head(tail(tail(a))) |
|
 个最大的元素,在以下的排序方法中,采用那一种最好( )。 个最大的元素,在以下的排序方法中,采用那一种最好( )。 |
| A:快速排序 B:堆排序 C:归并排序 D:基数排序和shell排序 |
|
| 非空的循环单链表(头指针为 head )的尾结点(由 p 指向)满足【 】。 |
| A:p->next==NULL B:p==NULL C:p->next==head D:p==head |
|
下面关于有向图运算的叙述:
(1)求有向图结点的拓扑序列,其结果必定是唯一的。
(2)求两个指向结点间的最短路径,其结果必定是唯一的。
(3)求AOE网的关键路径,其结果必定是唯一的。
其中,正确的是 ( ) |
| A:只有(1) B:(1)和(2) C:都正确 D:都不正确 |
|
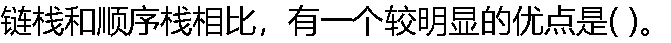 |
| A:通常不会出现栈满的情况 B:通常不会出现栈空的情况 C:插入操作更加方便 D:删除操作更加方便 |
|
| 排序方法中,从未排序序列中挑选元素,并将其依次放入已排序序列(初始为空)的后面的方法,称为【 】。 |
| A:希尔排序 B:归并排序 C:直接插入排序 D:直接选择排序 |
|
| 队列存放在 A[0..M-1] 中,则入队时的操作为【 】。 |
| A:rear=rear+1 B:rear=rear+1%M C:rear=rear+1%M+1 D:rear=rear+1%M-1 |
|
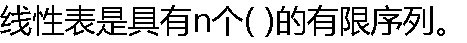 |
| A:表元素 B:字符 C:数据元素 D:信息项 |
|
 |
| A:顺序存储方式下数组所占的空间大小 B:链式存储方式下所有结点占用的空间大小 C:表中的元素个数 D:所能存储的最大的结点个数 |
|
| 由 8 个权值构造一棵哈夫曼树,该哈夫曼树有【 】个结点。 |
| A:15 B:16 C:17 D:14 |
|
| 设 A 是一个 n*n 的对称矩阵,压缩存储到一个一维数组 B[0..n(n+1)/2-1] 中,则下三角部分元素 ai,j 在 B 中的位置是【 】。 |
| A:ii-1/2+j-1 B:ii-1/2+j C:ii+1/2+j-1 D:ii+1/2+j |
|
| 顺序查找法适合于存储结构为【 】的查找表。 |
| A:散列存储 B:顺序存储或链式存储 C:压缩存储 D:索引存储 |
|
| 对于顺序存储的线性表,访问结点和增加、删除结点的时间复杂度为【 】。 |
| A:OnOn B:OnO1 C:O1On D:O1O1 |
|
| 不带头结点的单链表(头指针为 h )为空的条件是【 】。 |
| A:h==NULL B:h->next==NULL C:h->next==h D:h!=NULL |
|
| 对某个无向图的邻接矩阵来说,【 】。 |
| A:第i行上的非0元素个数等于第i列上非0元素个数 B:矩阵中非0元素个数等于图中的边数 C:第i行、第i列上非0元素个数等于顶点vi的度数 D:矩阵中非全0行的行数等于图中的顶点数 |
|
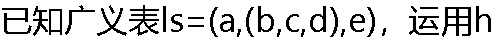 ead和tail函数取出ls中原子b的运算是( )。 ead和tail函数取出ls中原子b的运算是( )。 |
| A:head(head(ls)) B:tail(head(ls)) C:head(head(tail(ls))) D:head(tail(ls)) |
|
 为主序,A11为第一个元素,其存储地址为1,每个元素占1个地址空间,则A85的地址为( )。 为主序,A11为第一个元素,其存储地址为1,每个元素占1个地址空间,则A85的地址为( )。 |
| A:13 B:33 C:18 D:40 |
|
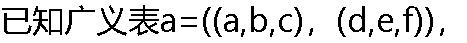 从a中取出原子e的运算是( )。 从a中取出原子e的运算是( )。 |
| A:tail(head(a)) B:head(tail(a)) C:head(tail(tail(head(a)))) D:head(tail(tail(a))) |
|
 的结果为( )。 的结果为( )。 |
| A:c,d B:(c,d) C:((c,d)) D:d,c |
|
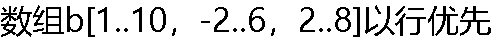 的顺序存储,设第一个元素的首址是100,每个元素的长度为3。元素b[5,0,7]的存储首址为( )。 的顺序存储,设第一个元素的首址是100,每个元素的长度为3。元素b[5,0,7]的存储首址为( )。 |
| A:900 B:912 C:910 D:913 |
|
| 若一棵二叉树具有 10 个度为 2 的结点, 5 个度为 1 的结点,则度为 0 的结点个数为【 】。 |
| A:9 B:11 C:15 D:不确定 |
|
 大致为 大致为 |
| A:O(1) B:O(n) C:O(1og2n) D:O(n2) |
|
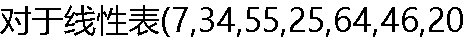 ,10)进行散列存储时,若选用H(K)=K %9作为散列函数,则散列地址为1的元素有( )个, ,10)进行散列存储时,若选用H(K)=K %9作为散列函数,则散列地址为1的元素有( )个, |
| A:1 B:2 C:3 D:4 |
|
 条边才能确保是一个连通图。 条边才能确保是一个连通图。 |
| A:5 B:6 C:7 D:8 |
|
 |
|
|
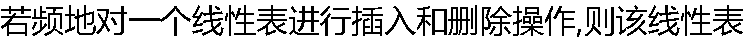 宜采用何种存储结构,为什么? 宜采用何种存储结构,为什么? |
|
|





